Dificultades para el procesamiento automático del euskeraEl euskera es un idioma altamente aglutinante, y esta característica dificulta mucho su procesamiento automático. De hecho, es necesario que tales procesos reconozcan la estructura de la lengua para que puedan dar buenos resultados. Supongamos que queremos hacer una búsqueda de la palabra euskara (lengua vasca) en un conjunto de textos. En el artículo que se muestra en la figura esta palabra aparece cuatro veces. Sin embargo, con un sistema informático habitual que puede ser de utilidad en muchos idiomas no sirve en nuestro caso. La razón es que todas las veces que aparece la palabra en este artículo se encuentra declinada, pero el sistema no sabe cuales son las terminaciones de las formas declinadas en euskera. Ahora supongamos que en el mismo artículo hay una palabra que no conocemos y la queremos buscar en un diccionario automatizado. Esta palabra podría ser egokituta (adaptado). Pero como tal, no aparece en ningún diccionario normal, sino únicamente egokitu (adaptar). Una vez más, para un procesamiento automático hace falta tener la información de cuál es el lema (forma básica) de la palabra en cuestión.
Figura 1 Por lo tanto, a diferencia de otros muchos idiomas, en el caso del euskera es prácticamente imprescindible el uso de la tecnología lingüística para obtener resultados adecuados en los procesos automáticos. Un corpus pequeño el del euskeraUn corpus es un conjunto de textos, que suele estar en formato electrónico. Según Beñat Oihartzabal, jefe de la sección de investigación de Euskaltzaindia (la Real Academia de la Lengua Vasca), "el corpus es una colección de datos lingüísticos que se suele utilizar en una lengua para describirla y analizarla." Para el desarrollo de muchos sistemas es imprescindible disponer de un corpus grande de ejemplos. Para el uso de la tecnología estadística, para la adecuación de sistemas y para otros muchos usos, los corpus son de gran valor para mejorar el rendimiento de procesos automáticos. En el caso del euskera carecemos de conjuntos documentales adecuados en formato digital para muchos campos. Lengua no normalizadaIgual que en otras muchas áreas, también para las nuevas tecnologías se derivan complicaciones de la falta de una normalización lingüística. Falta de parentescoComo es sabido, la lengua vasca carece de parientes conocidos. Por lo tanto, no existe la posibilidad de aprovechar recursos o logros realizados para lenguas emparentadas. Las diferencias entre el euskera y sus lenguas vecinas, la francesa y la española, son demasiado grandes para permitir el uso, tal cual, de lo que se haya desarrollado en éstas. De hecho, son de mucha más utilidad para nosotros los trabajos que se han hecho para el húngaro, por ejemplo, que los pertinentes a lenguas geográficamente más cercanas. Es muy importante la serie de trabajos hechos en los últimos años para superar tales dificultades en la Universidad del País Vasco, y concretamente en el equipo IXA (http://ixa.si.ehu.es/Ixa). ¿Qué hay y qué se puede hacer?Algunas de las herramientas y aplicaciones mencionadas en este artículo ya están desarrolladas y puestas a la disposición del público, pudiéndose descargar de los siguientes sitios del Gobierno Vasco y de la Universidad Vasca de Verano en Internet:
¿Cómo nos pueden ayudar las nuevas tecnologías a escribir en euskera, trabajar en euskera, y vivir en euskera? Intentaremos contestar esas preguntas por medio de algunos ejemplos. Algunos de los ejemplos que se citarán aquí ya existen, otros son proyectos a la espera de financiación, y aún otros son realidades ya existentes en otros idiomas. Pero todos representan posibilidades para el euskera de gran interés y perfectamente posibles si todos nos esforzamos en lograrlos. Unificación terminológica
Figura 2
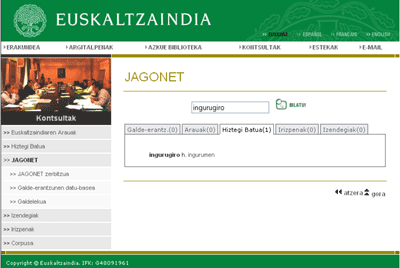
Sistemas para resolver dudas acerca de la lenguaDisponemos de más de un servicio gratuito en euskera que ofrecen al usuario la posibilidad de consultar sobre sus dudas acerca del uso más correcto. En ellos podemos leer las respuestas ya dadas a preguntas de otros usuarios, además de formular nuestras propias preguntas.
Figura 4
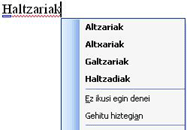
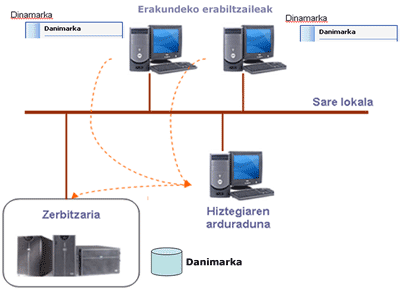
Muchas instituciones o empresas emplean a "técnicos de euskera" cuyo trabajo es aclarar dudas lingüísticas. Para tales entornos se han desarrollado aplicaciones informáticas para recibir información y llevar a cabo la comunicación. Un conocido ejemplo de este tipo de servicios es el ofrecido por la Universidad del País Vasco, llamado Ehulku (http://www.ehu.es/ehulku/), que está dirigido a los profesores y demás empleados de la universidad, y cuya función es promocionar el uso correcto y apropiado del euskera en el ámbito universitario. No es una escuela de idiomas ni tampoco un espacio para la discusión de investigaciones filológicas, sino un servicio que trata de buscar una solución adecuada para los problemas lingüísticos en la información y los servicios ofrecidos por la universidad en euskera. El mismo tipo de aplicaciones informáticas se utiliza para gestionar la aclaración de dudas sobre la lengua vasca en instituciones como el Gobierno Vasco, la Fundación Elhuyar, y la Diputación Foral de Vizcaya, entre otros. Diccionarios en nuevos formatosHan quedado atrás los tiempos en los que sólo había diccionarios de papel. Hoy día es común utilizar Internet para consultar un diccionario. Gracias al Gobierno Vasco, hoy día los principales diccionarios vascos tienen un sistema de consulta en Internet. El contenido de estos diccionarios se actualiza dos o tres veces al año, por lo que la información que está disponible en Internet es más actual que la que se puede obtener en la última versión en papel de estos diccionarios. Pueden usarse diccionarios vasco-castellano y vasco-francés como herramientas para facilitar la navegación en euskera. Muchas personas que saben euskera navegan en castellano o en francés por miedo de que puedan perder información a consecuencia de su desconocimiento de algunas palabras. Con las nuevas tecnologías, una consulta de diccionario puede ofrecerse con rapidez al ser activada por el usuario cuando encuentra una palabra que desconozca. Supongamos que mientras un usuario está buscando información en el sitio web en euskera de un banco o caja de ahorros, encuentra una palabra que no entiende: onuren, por ejemplo. Señalando la palabra con el ratón, pulsa una tecla determinada (por ejemplo, F12), con lo que se pone en marcha el sistema de consultas. El sistema lematiza la palabra, busca el lema en el diccionario, y muestra la traducción en una nueva ventana. Así hemos evitado que el usuario cambie de idioma, y puede seguir navegando en euskera. Puede parecer un paso pequeño para la normalización, pero debemos recordar que cuantos más navegadores haya en páginas en euskera, más materiales se pondrán en Internet en euskera en el futuro. (La mayoría de organizaciones que ponen información en el Internet en euskera comprueban el número de navegadores que la usan.)
Figura 5 Así tenemos la opción de comprobar las palabras en euskera que posiblemente no conozcamos. El mismo sistema puede usarse para hacer consultas de diccionario en sitios web en inglés, francés o castellano. Los mismos diccionarios pueden integrarse en el procesador de palabras Word, con lo cual el usuario puede realizar rápidas consultas sobre la traducción de una palabra determinada al leer o escribir, haciendo clic con el botón derecho sobre la palabra. Hasta el momento están disponibles en este formato el diccionario vasco-castellano de Elhuyar, el diccionario de sinónimos de UZEI y el diccionario Elhuyar euskera-francés. Diccionarios en el puesto de trabajo: para los que están trabajando en una institución o empresa, hay otras herramientas. Con ellas, desde un editor de texto, un sitio web o el Escritorio del ordenador, podemos seleccionar cualquier palabra y, pulsando una tecla, realizar una consulta de diccionario. Se pueden integrar diversos diccionarios en este tipo de sistemas. La firma Babylon (www.babylon.com) ofrece diccionarios de más de trece idiomas. En nuestro caso, podríamos incorporar todos los que están en formato de Internet. Diccionarios de bolsillo. Últimamente han proliferado mucho los ordenadores de bolsillo que ofrecen toda una serie de recursos como una agenda, un editor de textos, Internet, GPS, correo, etcétera.
Figura 6 Gracias a las nuevas tecnologías, también se pueden obtener diccionarios de este tipo en los ordenadores. Pueden incluir diccionarios para traducir entre el castellano, el inglés o el francés y el euskera, así como frases útiles para el viajero, etc. Sin duda esta es un área donde tendremos que trabajar en el futuro.
Figura 7 Sistemas de consulta de corpusA menudo no es suficiente ver una palabra en el diccionario, ya que la duda que tenemos gira en torno al uso de esa palabra: quisiéramos ver la palabra dentro de una frase, en un contexto. Muchas veces tal frase nos proporcionará una gama más amplia de información semántica. Hoy día, está disponible para ser consultada una amplia gama de obras literarias del siglo XX, así como muchos libros que han sido traducidos para la formación profesional, y por otro lado, artículos publicados en diarios y revistas. Corpus del siglo XX (http://www.euskaracorpusa.net/): Es un material de consulta que ofrece un corpus estadístico de 4.658.036 palabras de texto representando la lengua vasca del siglo XX. Su función es proporcionar un compendio y muestra del euskera que se ha usado y se usa hoy día, sin pretensión de proponer un lenguaje modélico. Prosa ejemplar de hoy (http://www.ehu.es/euskara-orria/euskara/ereduzkoa/): No pocos escritores, incluso en el ámbito universitario, tienen muchas dudas, al escribir sus artículos y otros materiales, sobre cuáles son las formas más correctas de algunas palabras, las expresiones más aceptables, o las construcciones más acertadas. El Servicio de Euskera de la Universidad del País Vasco ha proporcionado esta herramienta para dar soluciones, reuniendo en un corpus bastante amplio de textos recientes de escritores ejemplares contemporáneos en euskera, junto con un buscador potente y fácil de usar para obtener el máximo provecho de ese corpus. Así, se trata de una buena herramienta por medio de la cual podemos observar las soluciones a las dudas que podamos tener que han dado nuestros mejores autores vascos. De la mano de Lanbide Ekimena, podemos consultar numerosos libros de formación profesional (http://www.jakinbai.com/): LANEKI es una sociedad creada por iniciativa de HETEL y IKASLAN, con un plan de varios años para traducir materiales escolares al euskera y hacerlos disponibles en formato electrónico. El Corpus de Ciencia y Técnica que está siendo elaborado por la Fundación Elhuyar: Se trata de un corpus especializado ya que reúne textos que pertenecen al área científica y técnica. Se han incorporado al corpus textos que se han escrito y publicado en esta área entre 1990 y 2002. Además de trabajos originales en euskera, también se han incluído otros traducidos al euskera. Hay que mencionar también el sitio web de literatura creado por la editorial Susa. Llamado Armiarma, contiene muchas obras literarias (http://www.armiarma.com/). En otras muchas áreas, en cambio, no existen importantes colecciones de documentación hoy por hoy. Búsqueda de informaciónHoy día la masa de información disponible es enorme. Son innegables los beneficios de la existencia de esta gran cantidad de información, pero se siente la necesidad de combinar cantidad con calidad. Si no tenemos buenas herramientas para la búsqueda de la información, esta puede sernos de poca utilidad. No pocas veces cuando acudimos a Internet, por ejemplo, como principal fuente de información, en busca de algún dato específico, aquello que buscamos se pierde en medio de una masa de información que tiene poco o nada que ver con lo que necesitamos.La siguiente figura muestra lo que pasará si buscamos en el portal www.euskadi.net la palabra beka ("beca"):
Figura 8 Como se ve, el uso de la tecnología lingüística es muy importante para la búsqueda de información en vasco. Localización de softwareEs muy importante que las aplicaciones ofimáticas, de correo electrónico o los sistemas operativos de uso diario estén en nuestro idioma. Es una tarea difícil, porque tales aplicaciones se actualizan a menudo y poner todas las versiones del software en euskera requeriría un presupuesto muy grande. Con todo, existen algunas aplicaciones en euskera, las más importantes de las cuales pueden obtenerse de los dos sitios web ya mencionados. Digitalización de la información OCR significa Optical Character Recognition (Reconocimiento Optico de Carácteres). Normalmente si escaneamos un texto impreso en papel el resultado será una imagen que no podemos manipular o revisar en un procesador de palabras. Los sistemas de OCR sirven para que después de escanear un texto, el ordenador lo pueda entender como texto. Dicho de otro modo, OCR es el reconocimiento por ordenador de carácteres de texto escritos o impresos. Esto quiere decir que cuando usamos OCR escaneamos cada carácter como si fuera una foto y después esa imagen escaneada es analizado y convertido a un código de carácter corriente (de ASCII, por ejemplo). En muchos campos los sistemas de OCR son utilizados a diario: por ejemplo, las bibliotecas y archivos de documentos lo emplean para digitalizar y almacenar sus archivos. Por otro lado, millones de revistas y cartas se clasifican diariamente usando OCR para agilizar la distribución del correo. Se ha desarrollado OCR para uso con el euskera; por lo tanto, hoy día los libros y papeles en euskera pueden ser escaneados y convertidos a texto. Como en cualquier otro idioma, el resultado del OCR necesita ser corregido a mano, ya que estos sistemas no pueden garantizar resultados 100% libres de errores. TraducciónGrandes cantidades de información se traduce del español euskera y viceversa todos los días. Herramientas llamadas Traducción Asistida por Ordenador o CAT (Computer Aided Translation) nos ayudan a traducir al recordar lo que las personas han traducido, almacenándolo, y cuando algo parecido se tiene que traducir otra vez, proponiendo la traducción anterior. De ese modo se aprovecha más eficazmente el trabajo ya hecho por el traductor. Esas aplicaciones crean una memoria de lo que se ha hecho; la base de datos donde se recoge la información se llama una memoria de traducción. Durante los últimos quince años, aplicaciones para la gestión de memorias de traducción se han convertido en herramientas esenciales en la industria de la traducción. Además de permitir que se traduzca más de prisa, también ayudan a garantizar la calidad de la traducción. Las memorias de traducción son muy útiles cuando hay que traducir documentos que pertenecen a una especialidad determinada (administración, derecho…). Son muy útiles cuando ciertas frases y expresiones se repiten mucho entre documentos, ya que pueden proponer automáticamente una traducción previamente almacenada en la memoria.
Figura 9
Traducción automáticaEl Periódico de Catalunya se publica todos los días en castellano y en catalán. Los periodistas escriben el periódico en castellano y luego el traductor automático lo traducen al catalán. Un equipo de revisores corrige el texto, y está listo para publicar junto con la versión en castellano. También son utilizados los traductores automáticos como herramienta de ayuda para navegar por Internet. Si necesito leer un sitio web alemán y no entiendo el alemán, usando un traductor automático puedo ver el sitio web en inglés o en español. La traducción no será completamente correcta, pero se consigue una aproximación a la información que contiene. Estos son los dos objetivos principales de los traductores automáticos: como ayuda para la traducción y para identificar contenido. Hay muchos traductores automáticos en el mundo. Los que traducen entre el inglés, el francés, el alemán y el castellano han existido desde hace muchos años. Los catalanes tienen dos o tres sistemas, los gallegos también uno, pero aún no hay ningún sistema de este tipo para el euskera. Pronto se inaugurará el primer sistema de traducción automática del español al euskera. Este traductor, llamado OpenTrad (www.opentrad.com), se ha desarrollado aprovechando la experiencia de los catalanes y el trabajo del grupo vasco IXA. Aunque queda mucho por hacer, ya se han dado los primeros pasos en este campo. El perfeccionamiento de los resultados producidos por el sistema se logrará a través de proyectos específicos, adecuando la aplicación a las necesidades de cada cliente o proyecto. Todavía está pendiente la creación de un sistema para traducir del euskera al castellano o al inglés. Hoy día se puede navegar por el sitio web de la Diputación Foral de Guipúzcoa en catalán a pesar de que la información colocada allí no está originalmente en catalán.
Comunidades virtuales
|
| Fecha de la última modificación: 07/06/2006 |